SpiceyPy 和 mice 的一些差异
2023-01-10 18:00:00

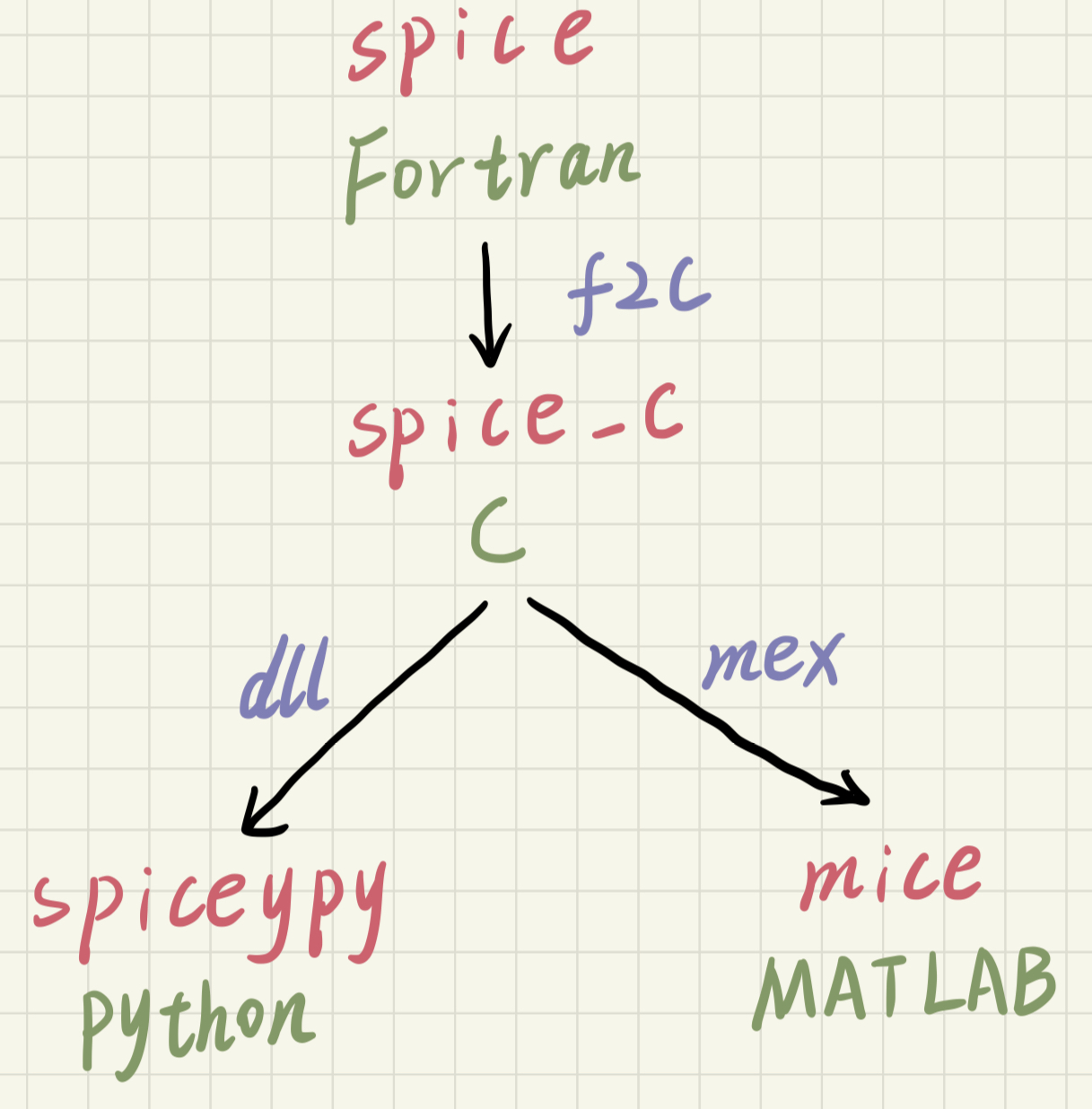
SpiceyPy 是 Python 版本的 SPICE 工具箱,mice 是 MATLAB 版本的 SPICE 工具箱。SpiceyPy 和 mice 用起来有一些差异,尤其是先接触 mice 再接触 SpiceyPy 的用户,这里主要介绍三点不同:Not Found Errors、向量化、spkw09()。
Not Found Errors
mice 带有查询性质的函数的末尾返回参数往往是一个布尔型变量found,表示是否查询到。举个例子,可以用下面的代码查询'Earth'对应的 id:
[id, found] = cspice_bodn2c('Earth')
如果内核认识'Earth',那么found为true,否则found为false。再比如,可以用下面的代码查询 id 为 1 的 frame 的信息:
[cent, frclss, clssid, found] = cspice_frinfo(1)
如果内核存在该 frame,那么found为true,否则found为false。
但是,SpiceyPy 引入了 Not Found Errors 机制,初学者极易在此产生困惑。还是用frinfo()函数举例子,我们在 Jupyter Notebook 里进行演示,先导入 SpiceyPy 库:

然后查询 id 为 1 的 frame 的信息:
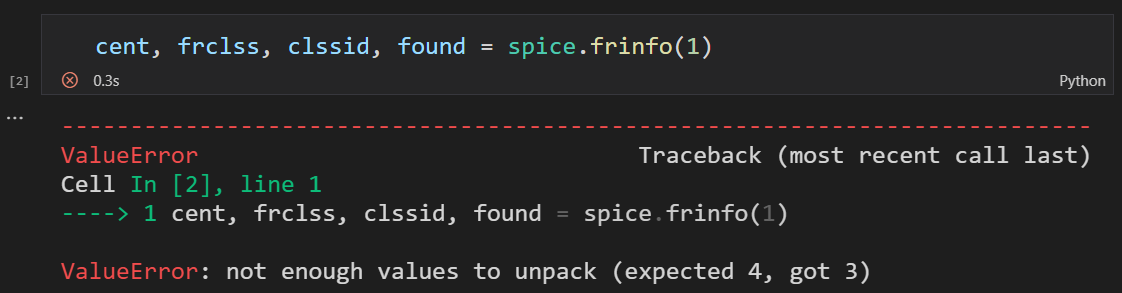
报错,说我们期望的返回值是 4 个,但是实际返回值是 3 个,因此无法完成解包操作。

然而 API 给的该函数就是 4 个返回值啊???
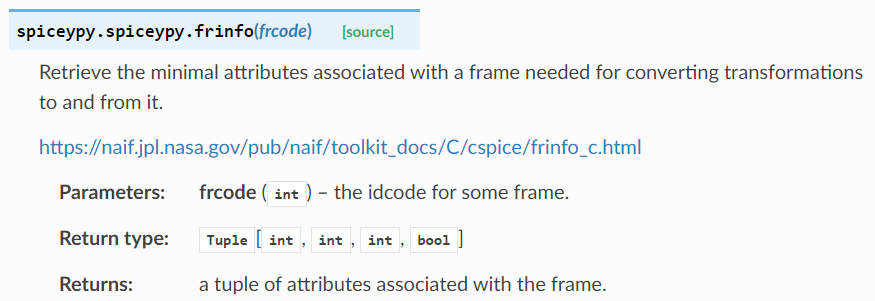

打开frinfo()函数的源代码,可以看到的确 return 了 4 个值,而且最后一个是布尔型:
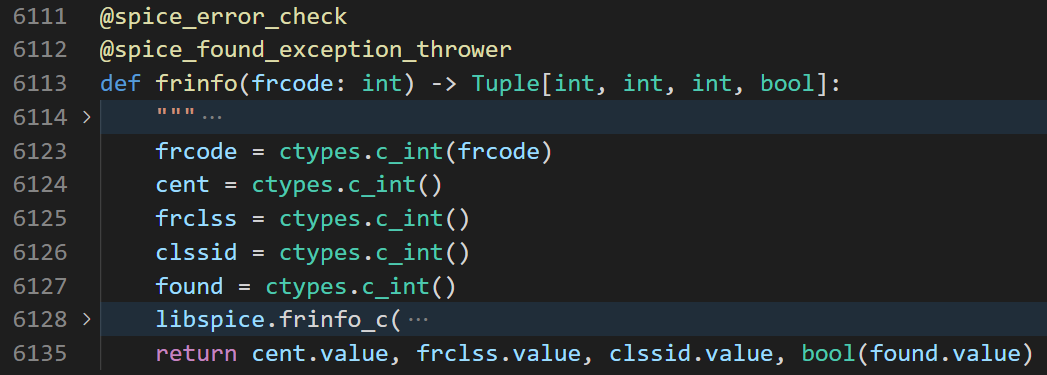
不妨用元组来接收返回值,看看到底返回了什么:

不出所料,结果只有 3 个,还是没有预期的最后一个布尔型变量。

真相是这样的,frinfo()函数外面套了一个叫做@spice_found_exception_thrower的装饰器,见源代码 6112 行,这个装饰器的作用是在frinfo()函数返回前,对返回值进行拦截。如果found为True,那么在最终返回值里剔除found,只返回前 3 个;如果found为False,则直接抛出异常NotFoundError。NotFoundError是 SpiceyPy 内置的一种异常,关于它的更详细解释可以查看官方文档。
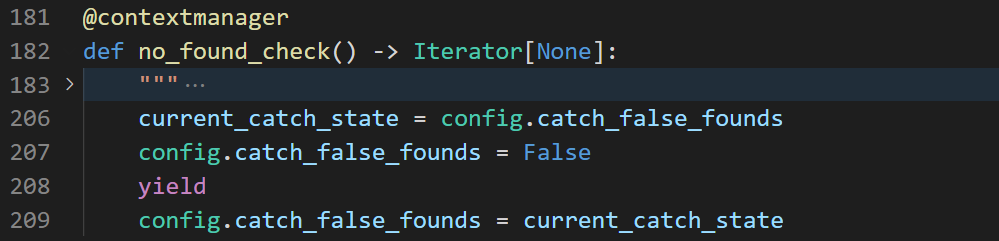
官方文档指出,SpiceyPy 默认是开启NotFoundError侦测的,如果想暂时关闭它,可以通过如下的方式:

此时便有了 4 个返回值,最后一个为True,可见的确是我们期望的结果。

需要注意的是,no_found_check()只是暂时关闭侦测,也就是在with语句之内都是遵守 API 的,with语句之外依然进行侦测(严谨地说,应该是with语句之外恢复之前的状态)。可以查看no_found_check()函数的源代码来证明这一点,yield之前config.catch_false_founds被设为了False,yield之后config.catch_false_founds被设为了之前的状态。
我们在with语句之外再试一次,可以看到又变为 3 个输出了:

如果想长久地关闭NotFoundError,可以用found_check_off()函数。关闭后如果再想打开,可以用found_check_on()函数。可以用get_found_catch_state()函数获得当前是否开启了NotFoundError。
这种末尾返回参数是found的函数有很多,使用时需多加注意,列举如下:
| 函数 | 函数 | 函数 | 函数 |
|---|---|---|---|
| bodc2n | dlabbs | gcpool | srfcss |
| bodn2c | dlabfs | gdpool | srfs2c |
| bods2c | dlafns | gipool | srfscc |
| ccifrm | dlafps | gnpool | srfxpt |
| cidfrm | dnearp | inedpl | stpool |
| ckfrot | dskxsi | kdata | surfpt |
| ckfxfm | dtpool | kinfo | surfpv |
| ckgp | ekgc | kxtrct | szpool |
| ckgpav | ekgd | sincpt | tkfram |
| cnmfrm | ekgi | spksfs | vprjpi |
| dafgsr | frinfo | srfc2s |
向量化
用 mice 的时候习惯了向量化,即绝大多数函数都能输入矩阵、返回矩阵,省去了相当多的 for 循环,不仅提高了代码可读性,更大大提高了计算效率,非常契合 MATLAB 的内涵。但是,刚转到 SpiceyPy 往往还保留着向量化的(先进)编程思维,可是 SpiceyPy 是对 C 语言版本忠实的翻译,C 语言版本的 API 是什么样,SpiceyPy 不会轻易改动,这就导致 SpiceyPy 和 mice 的不少函数存在使用差异。
举个例子,reclat()函数用来把直角坐标转为经纬坐标,在 SpiceyPy 中,它接受 1 个直角坐标,返回对应的 radius, longitude 和 latitude,还是在 Jupyter Notebook 里进行演示,先导入 SpiceyPy 库:

比如输入直角坐标 (1, 1, 1),结果如下:

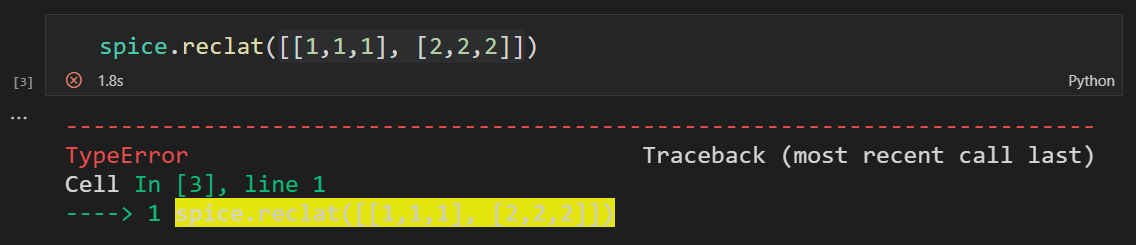
当我们尝试输入两个直角坐标,则会报错:

如果想一次性转换多个直角坐标,可以使用 for 循环:

对于大量的数据,我们对比一下 for 循环和 numpy 提供的向量化函数apply_along_axis()的运行效率:
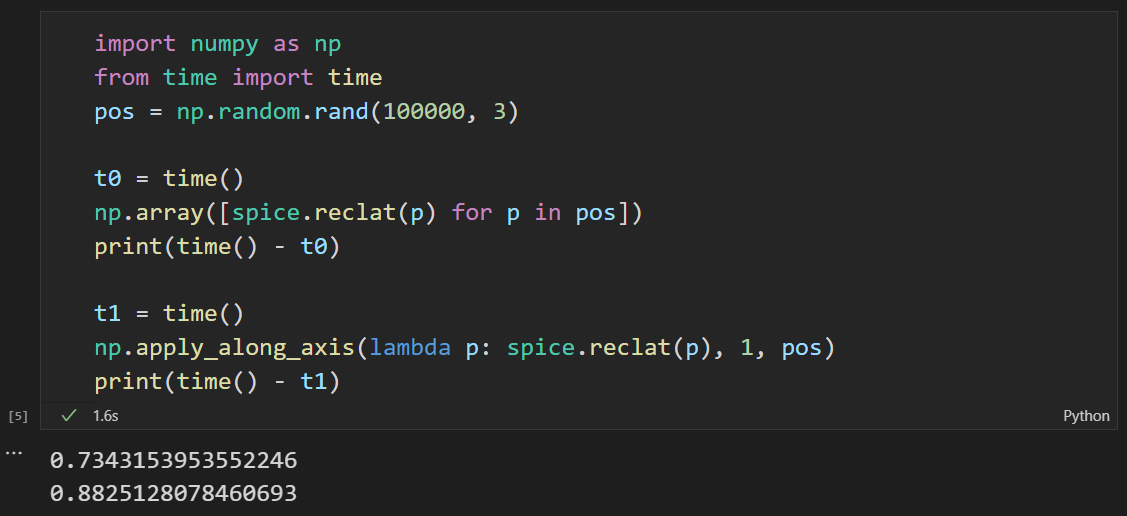
结果表明 for 循环略胜一筹。
如果在 MATLAB 命令行输入:
>> cspice_reclat([1,1,1; 2,2,2])
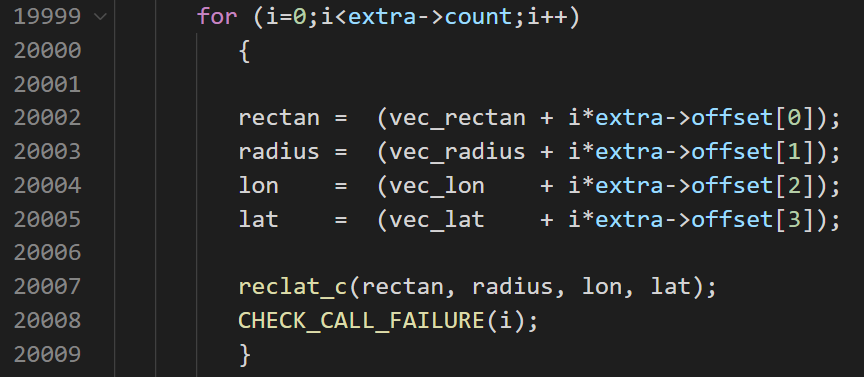
是可以正常运行的。那么为什么 mice 可以做到向量化?打开 mice.c 的源代码,可以看到 for 循环出现在这里,for 循环里的reclat_c()函数仍然只能一次转换一个直角坐标。也就是说 mice 在代码移植的时候就考虑了向量化,而 SpiceyPy 则没有。
spkw09()
在 mice 中,cspice_spkw09()函数接收 10 个参数,如下图所示:
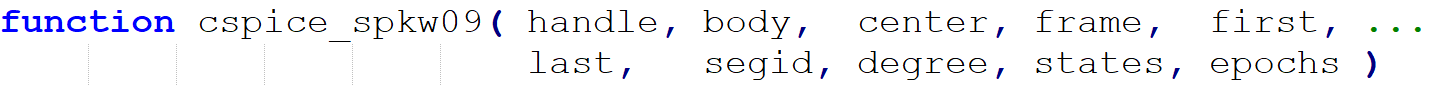
而在 SpicePy 中,spkw09()函数接收 11 个参数,如下图所示:
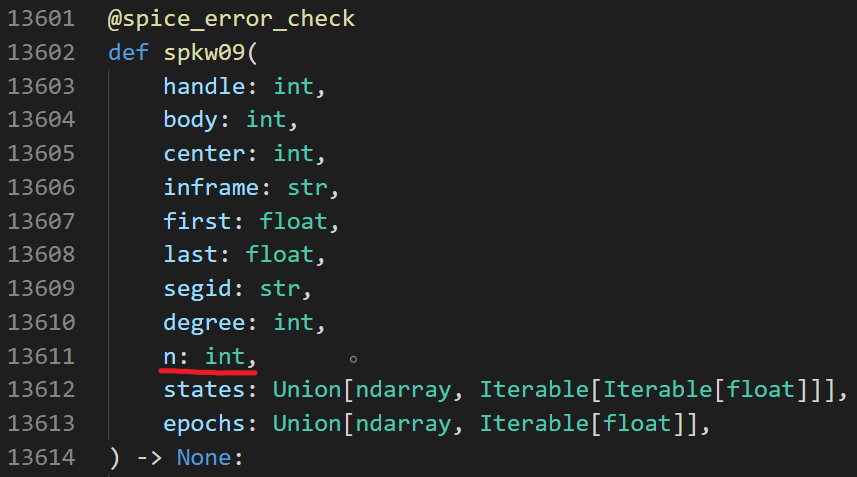
区别在于,SpicePy 比 mice 多了一个参数n,代表states的元素个数。前面说过,SpiceyPy 是对 C 语言版本忠实的翻译。对于 C 语言来说,传入一个数组名给函数,函数是没法知晓该数组有多少元素的,因为数组名本质上是数组首元素的地址。故传入数组名给函数的同时,通常还要把数组的元素个数一并传给函数,这也就是为什么会有一个参数n的原因。
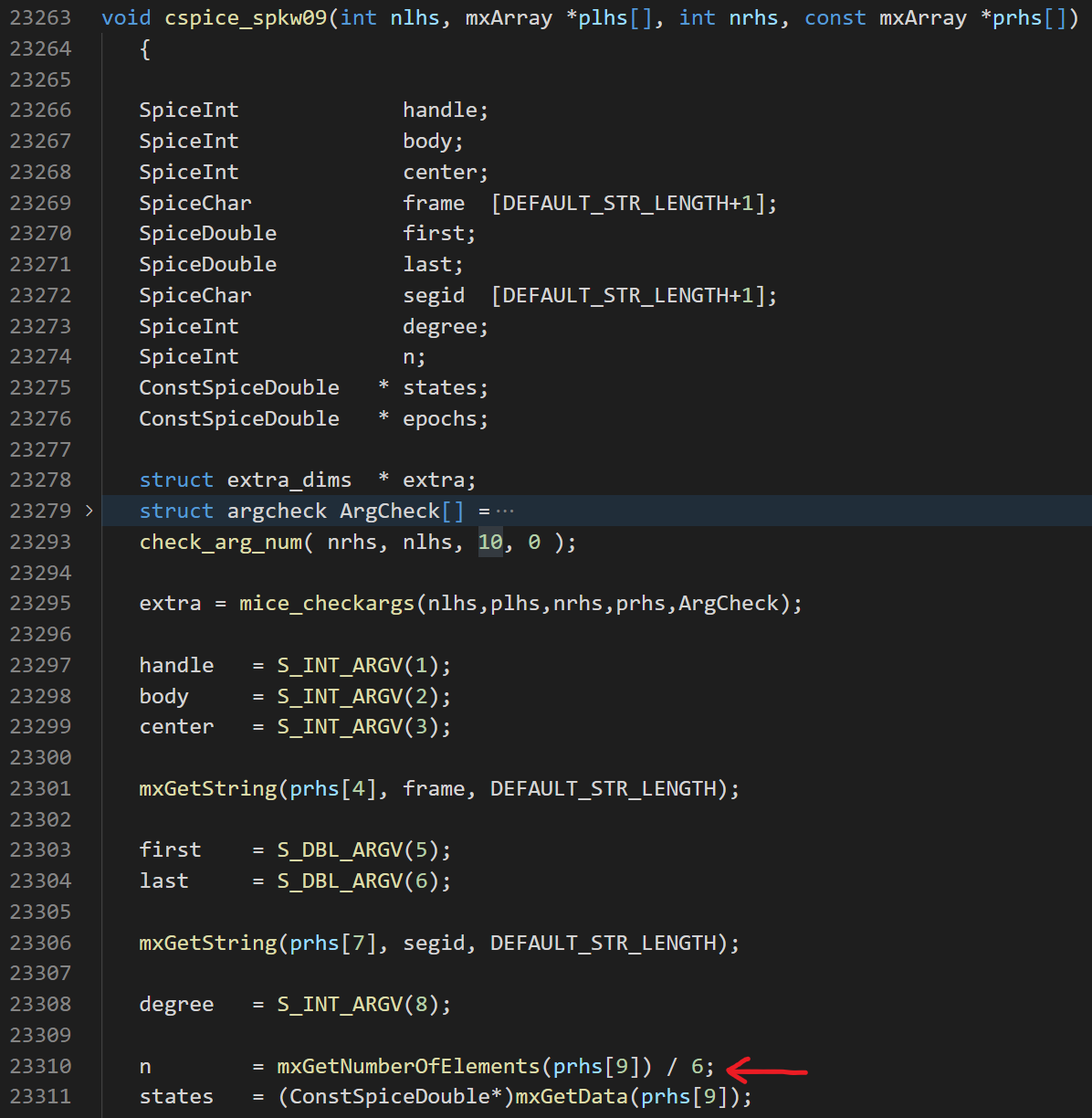
那么为什么 mice 不用传参数n呢?打开 mice.c 的源代码,可以看到n是在接口函数里被自动计算出来的,不用我们手动指定。
SpiceyPy 和 mice 的一些差异